
Insights
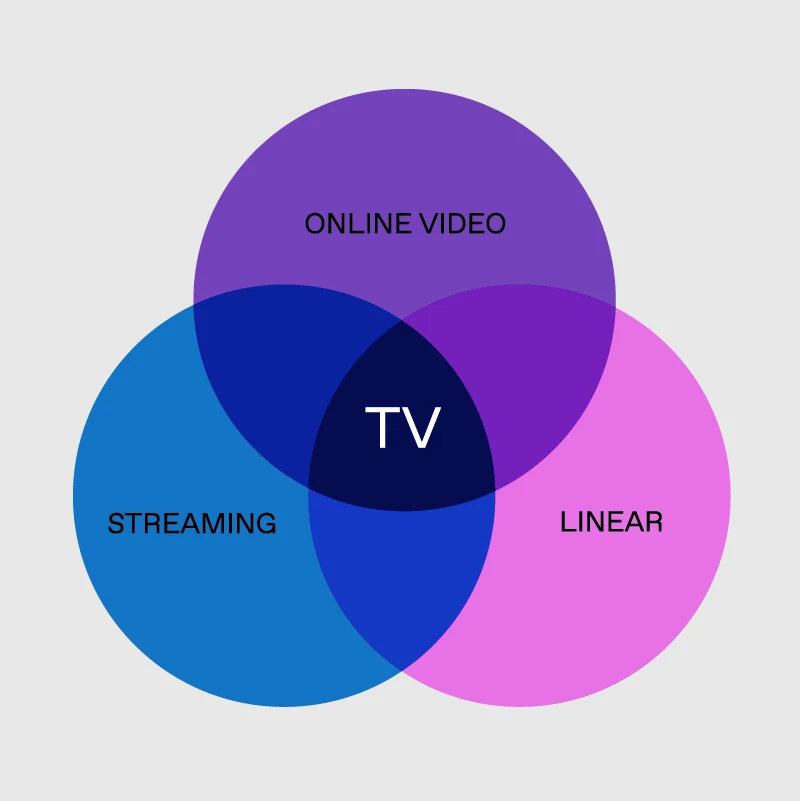
As Linear’s Definition Gets Muddier, It’s Time to Talk ‘Convergent TV’
Are you caught in the debate over what constitutes streaming versus linear TV? Our latest blog dives into the blurred lines of the two advertising channels, advocating for a single categorization of convergent TV.
Read more

Tatari Powers Next Generation of Agencies Entering TV Ad Market
Since announcing the availability for agencies to license Tatari 18 months ago, more than 30 agencies have signed on, with 40% buying into additional services.
Read more

Programmatic TV Tax Day is Not Just April 15. It's Every Day
This blog examines the significant "AdTech tax" in Connected TV advertising, advocating for Tatari's direct integration with publishers to bypass hidden fees, resulting in substantial cost savings and enhanced transparency.
Read more

How True Classic Used Convergent TV to Unlock Growth
We sat down with True Classic at GROW LA to discuss how their brand leverages convergent TV (linear, streaming, and online video) to drive growth.
Read more
The Reality of AI Investment: Lessons from Tatari's Approach
Tatari's strategic approach to leveraging AI across its TV advertising tools is a fundamental component of our business model, enabling significant growth and market expansion.
Read more
Tatari Makes Significant Updates and Improvements to its TV Ad Measurement
Our latest update enhances TV ad measurement accuracy by improving device graph data, incorporating stricter filters, and integrating with Vault's Data Clean Room.
Read more

CTV Fraud Should Never Be an Issue
To combat CTV fraud, we recommend direct purchases from publishers and outcome-based TV measurement as effective strategies to ensure advertising transparency and accountability.
Read more

A Unified Measure: The Case for Standardizing 'Outcomes' in TV Advertising
Discover the changing face of TV advertising measurement, from traditional viewer metrics to outcome-based approaches, and the potential benefits for advertisers and publishers alike.
Read more

International Women's Day 2024: #InspireInclusion
In recognition of International Women's Day, this blog post shares how a few of the women at Tatari and TheViewPoint #InspireInclusion.
Read more

Is Walmart's VIZIO Move a Masterstroke in the Media Retail Game?
Walmart's $2.3 billion acquisition of VIZIO catapults the retail giant into the TV landscape, promising a strategic challenge to Amazon's dominance by leveraging access to VIZIO's 18 million TVs.
Read more